Journal of Computational Design and Engineering
Combining Behavior Cloning and Reinforcement Learning for Architectural Space Layout Design
Digital Building Technologies — ETH Zürich
Abstract
From cold-start RL to demonstration-guided layout agents.
Generating architectural floor plans that satisfy geometric and topological requirements is a combinatorial design task. Pure reinforcement learning agents can search this space but require millions of environment steps before they produce useful layouts.
We introduce a hybrid pipeline that first imitates a corpus of human-designed plans through behavior cloning, then refines the policy with PPO using the SpaceLayoutGym environment. The combined agent reaches higher reward and produces layouts that better satisfy area, proportion, and adjacency constraints than either method alone.
Method
Two stages, one policy network.
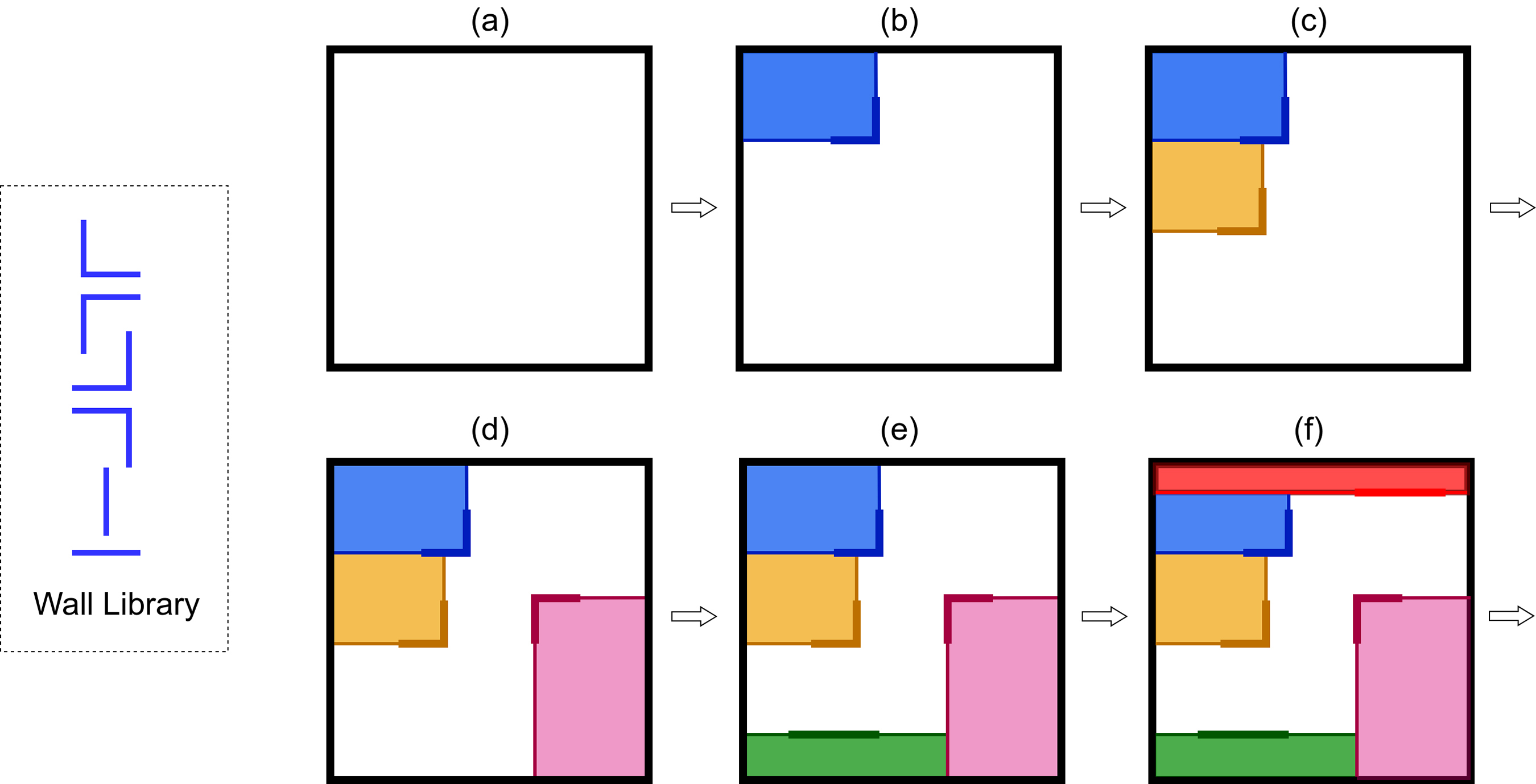
The agent composes a layout by placing laser-walls one at a time inside SpaceLayoutGym. The same actor-critic network is used in both training stages, so behavior-cloning weights transfer to PPO without re-architecting the policy.
- Stage 1
- Behavior cloning on a corpus of human-designed floor plans. Supervised loss over discrete wall-placement actions.
- Stage 2
- PPO fine-tuning against the area / proportion / adjacency reward, initialized from the cloned policy.
- State
- Partial-layout image plus a design-brief feature vector.
- Environment
- SpaceLayoutGym — OpenAI Gym-compatible, multi-scenario.
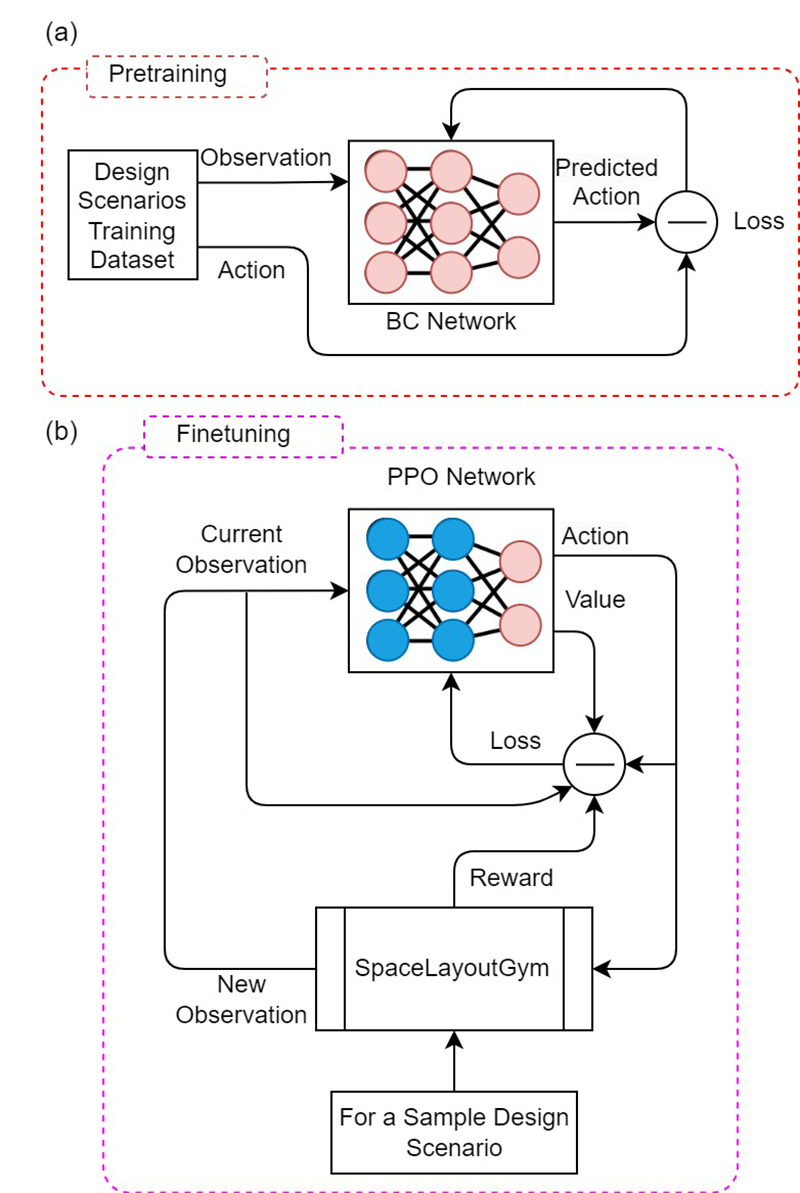
Framework
SpaceLayoutGym, with imitation in front of it.
Scenario generation feeds both the demonstration extractor and the live environment. Behavior cloning first produces an initial policy from design examples; PPO then refines that policy through interaction with SpaceLayoutGym.
This structure keeps the policy grounded in human-like layout sequences while still optimizing against measurable geometric and topological constraints.
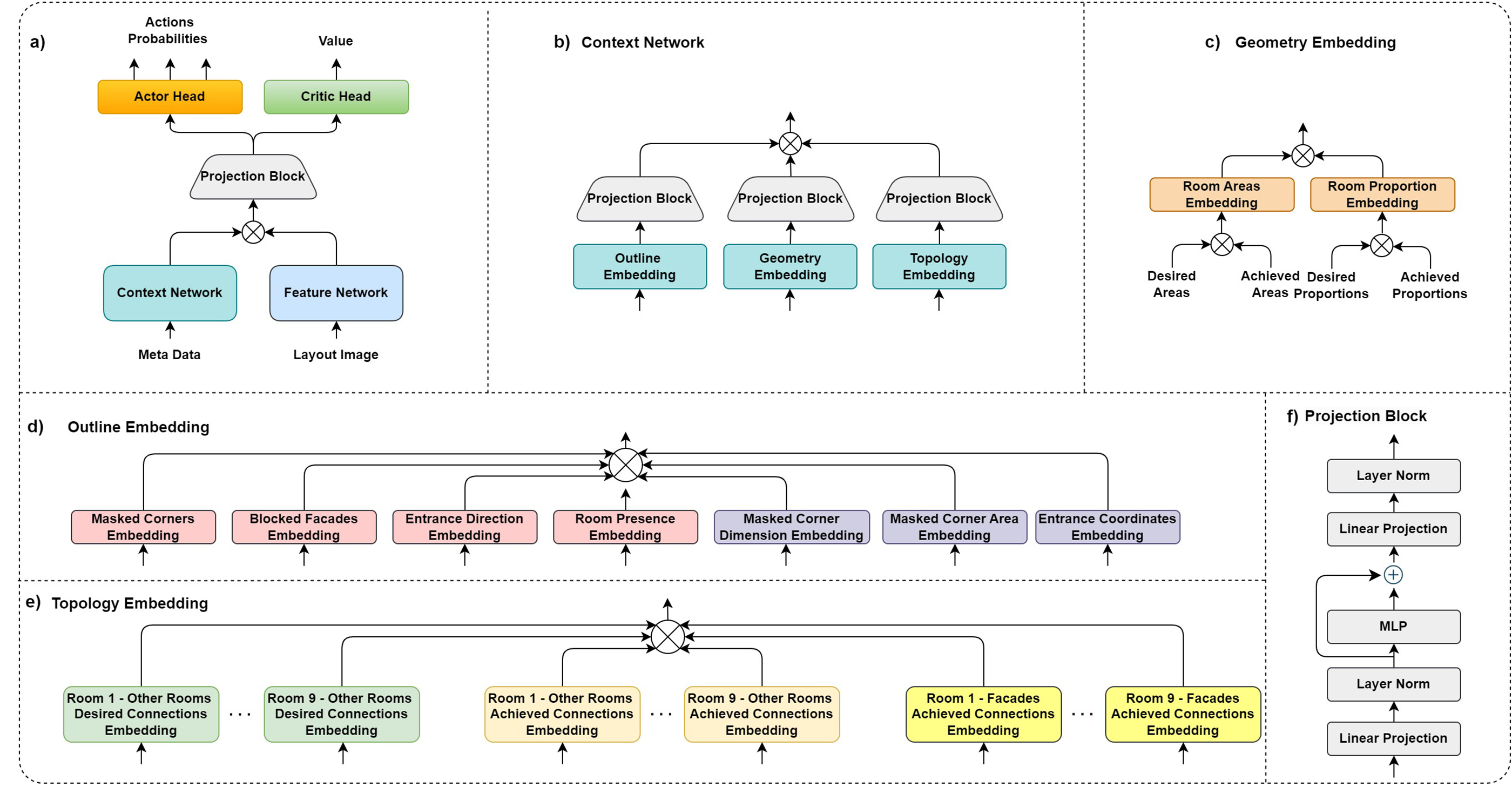
Keeping the network identical between stages is what makes the warm-start cheap: the BC checkpoint loads into PPO with no surgery. The encoder processes the partial-plan image and the design brief jointly, so the policy is conditioned on what the room needs, not just on what is already drawn.
SpaceLayoutGym exposes the standard Gym interface used in our 2024 paper, so the experiments here are directly comparable.
Results
BC + PPO outperforms PPO from scratch on every metric.
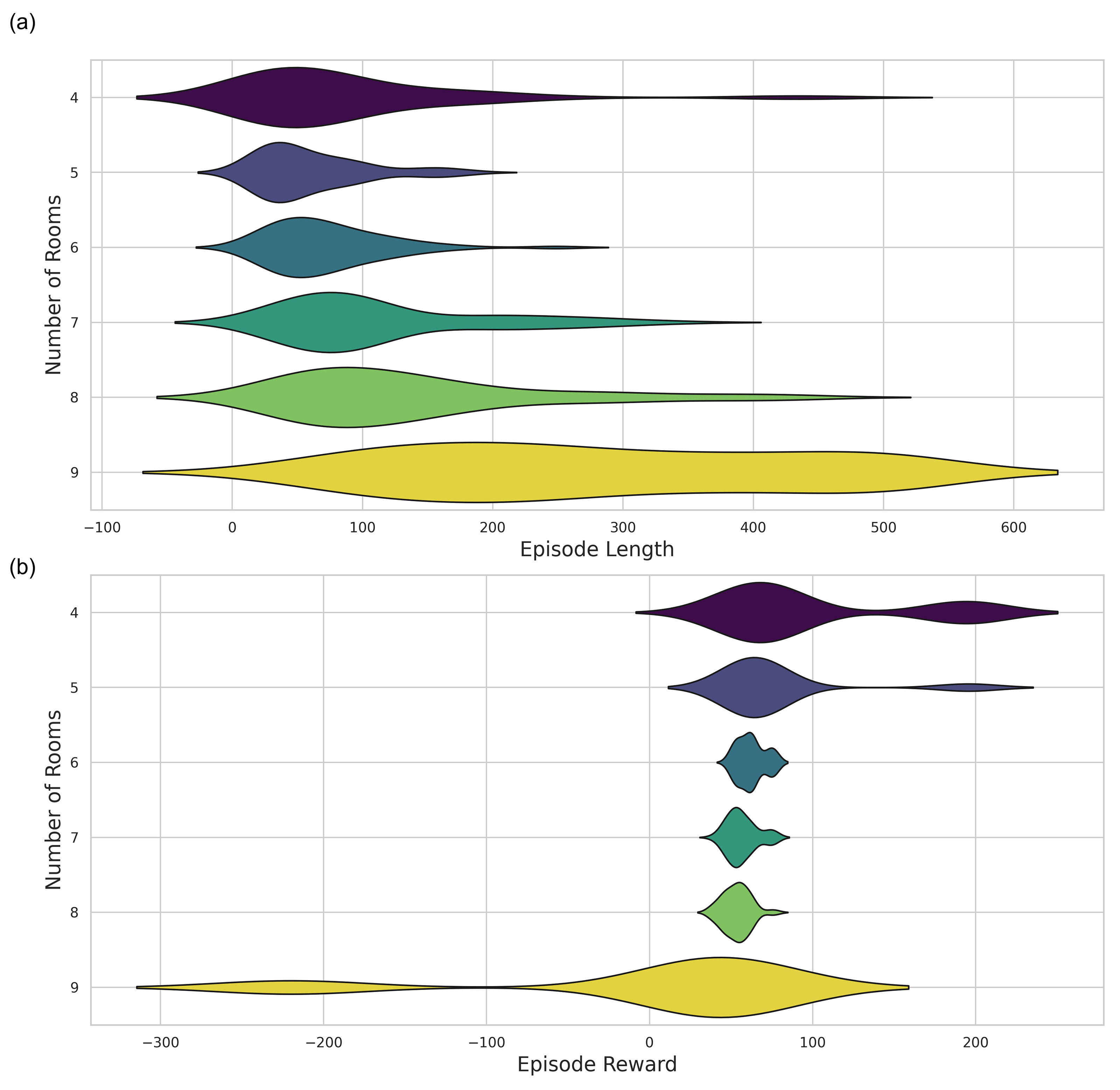
Three configurations are compared head to head: PPO from scratch, BC alone, and the combined BC + PPO pipeline. PPO from scratch eventually solves the easier scenarios but plateaus on hard constraint sets; BC produces plausible plans immediately but does not maximize reward; the combined agent inherits BC's design conventions and pushes reward higher with PPO.
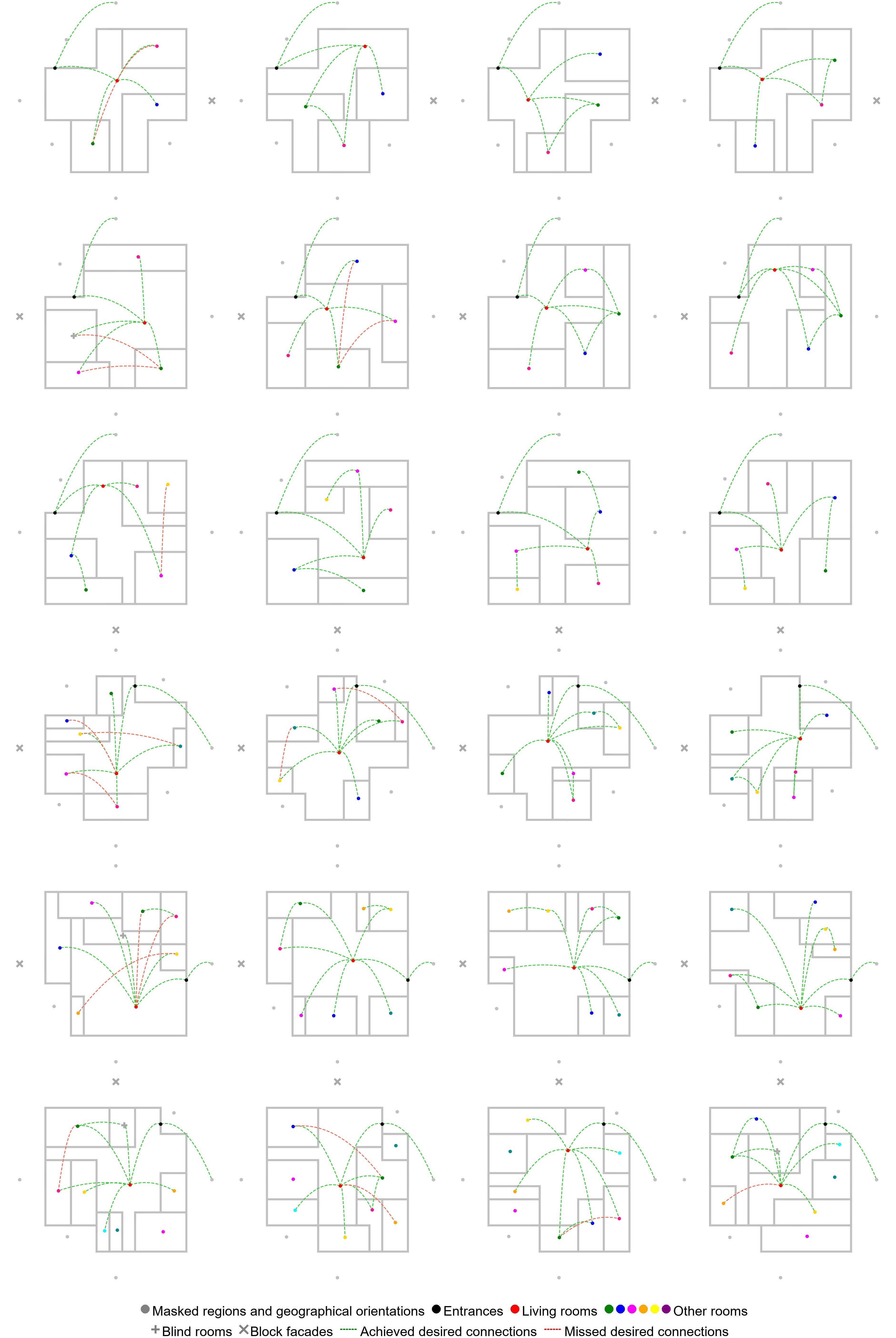
The practical takeaway: a moderately sized demonstration corpus shortens the wall-clock cost of training a layout agent and aligns the resulting policy with how human designers compose plans.
View the SpaceLayoutGym repository →Cite
BibTeX.
@article{kakooee2025bcppo,
title = {Combining Behavior Cloning and Reinforcement Learning
for Architectural Space Layout Design},
author = {Kakooee, Reza and Dillenburger, Benjamin},
journal = {Journal of Computational Design and Engineering},
year = {2025},
note = {To appear}
}See also our prior work: Reimagining Space Layout Design through Deep Reinforcement Learning — JCDE 2024 .