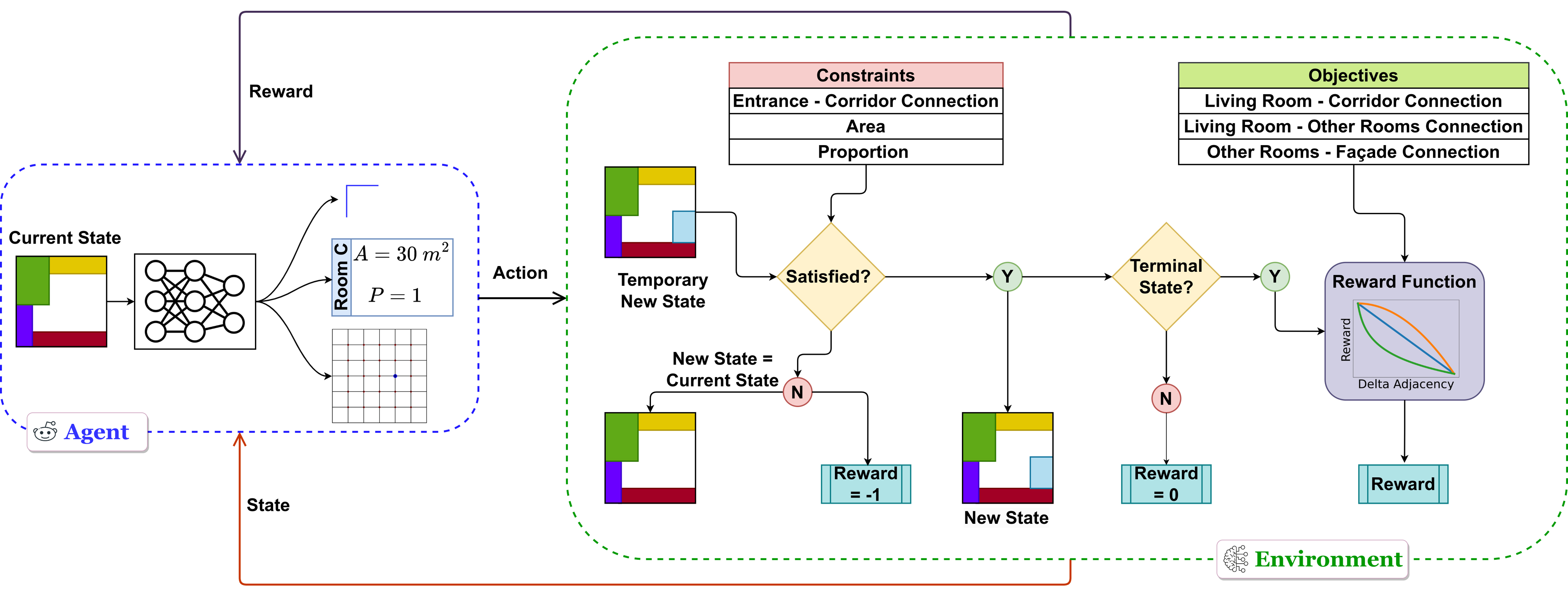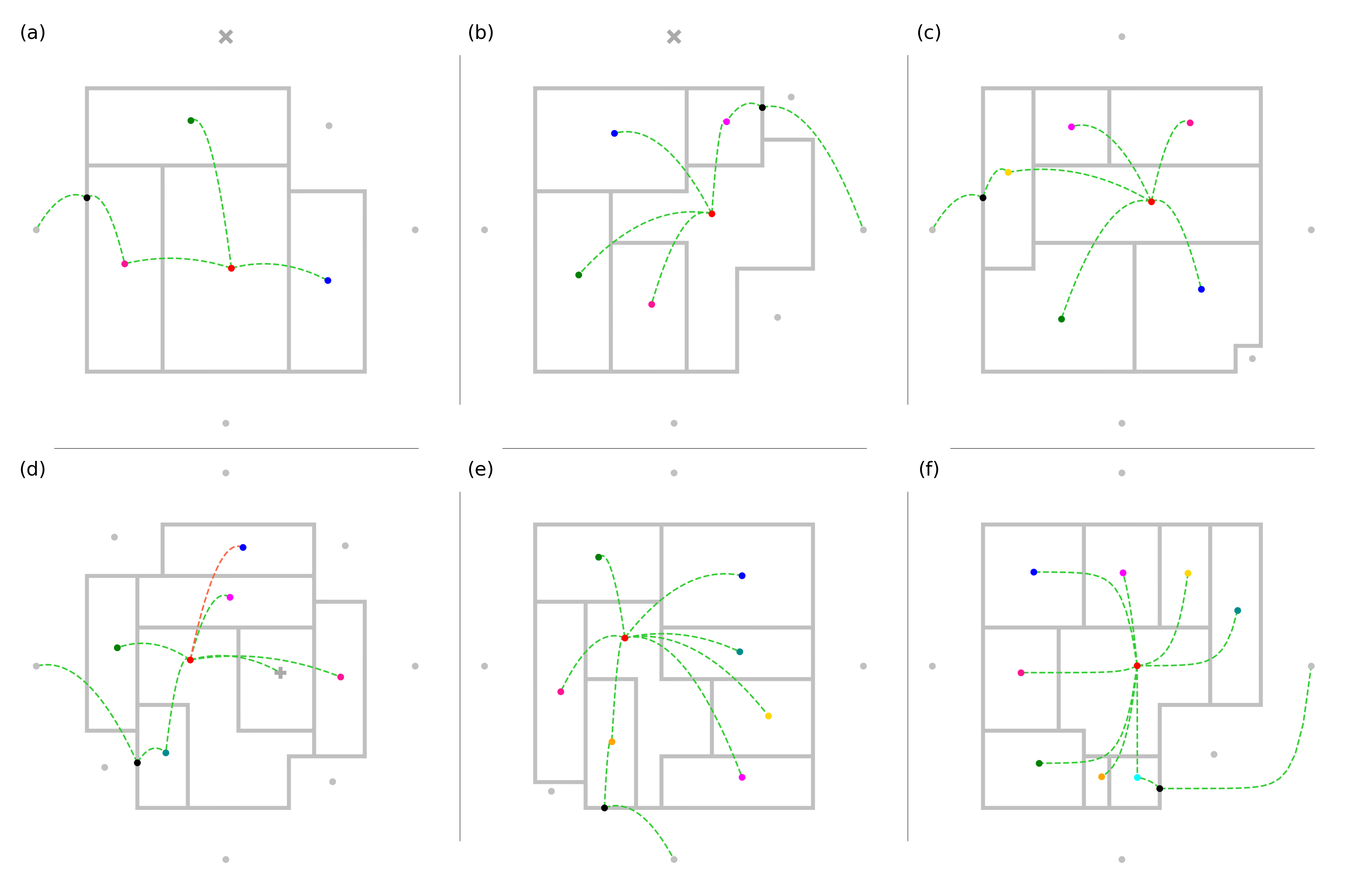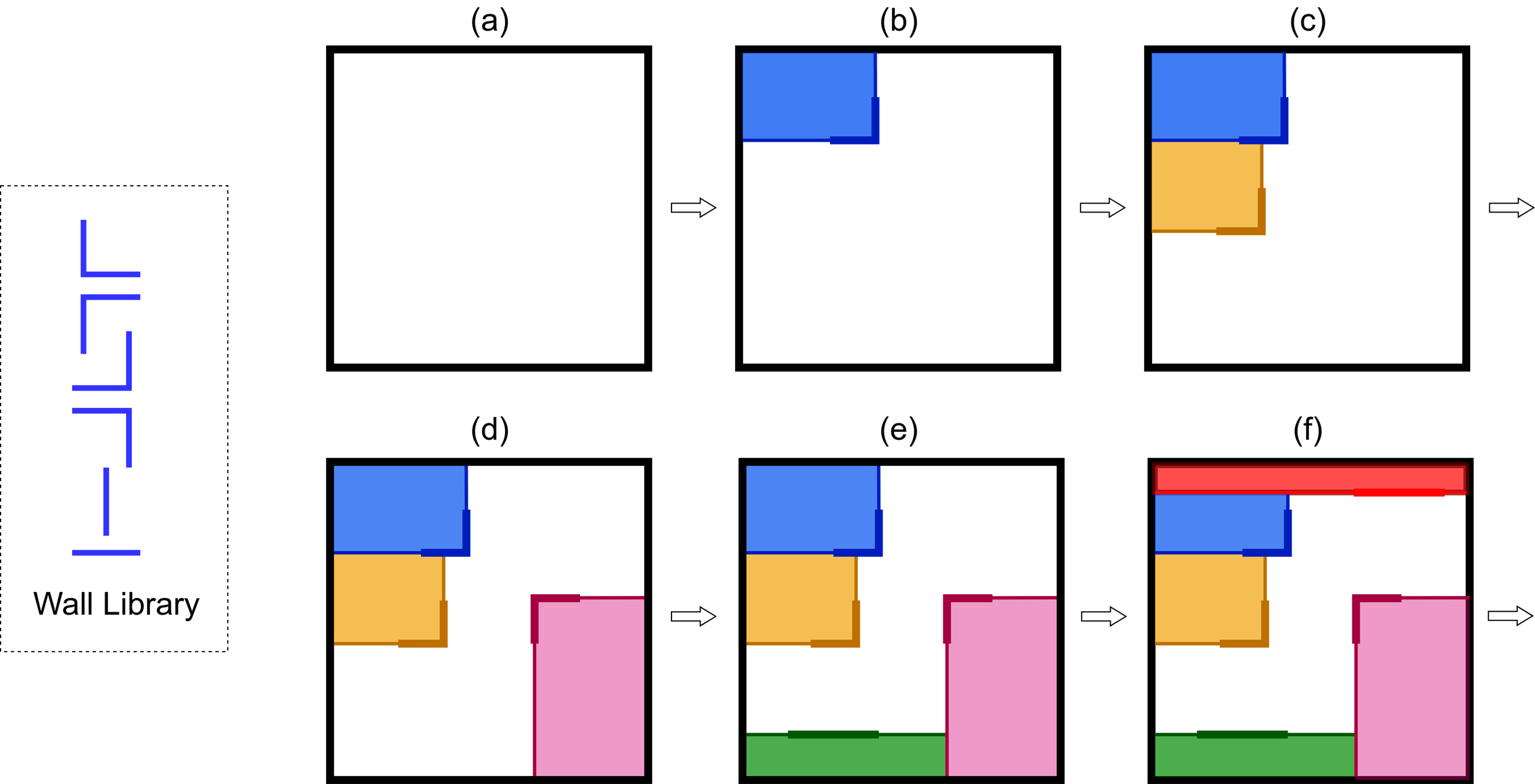
Equation 1
min
|Adj - Adj*|
s.t.
A ≥ Amin
|A - A*| ≤ Ath
1 ≤ P ≤ P*
(C, E) ∈ Adĵ
The formulation minimizes the difference between achieved and desired adjacencies while enforcing area, proportion, and entrance-to-corridor constraints during layout generation.